Abstract
Text-to-image models are powerful tools for image creation. However, the generation process is akin to a dice roll and makes it difficult to achieve a single image that captures everything a user wants. In this paper, we propose a framework for creating the desired image by compositing it from various parts of generated images, in essence forming a Generative Photomontage. Given a stack of images generated by ControlNet using the same input condition and different seeds, we let users select desired parts from the generated results using a brush stroke interface. We introduce a novel technique that takes in the user's brush strokes, segments the generated images using a graph-based optimization in diffusion feature space, and then composites the segmented regions via a new feature-space blending method. Our method faithfully preserves the user-selected regions while compositing them harmoniously. We demonstrate that our flexible framework can be used for many applications, including generating new appearance combinations, fixing incorrect shapes and artifacts, and improving prompt alignment. We show compelling results for each application and demonstrate that our method outperforms existing image blending methods and various baselines.Problem
Text-to-image models are powerful tools for image creation. However, these models may not achieve exactly what a user envisions. For example, the prompt "a robot from the future" can map to any sample in a large space of robot images. From the user's perspective, this process is akin to a dice roll. In particular, it is often challenging to achieve a single image that includes everything the user wants: the user may like the robot from one generated result and the background in a different result. They may also like certain parts of the robot (e.g., the arm) in another result.Key Idea
In this paper, we propose a different approach -- we suggest the possibility of synthesizing the desired image by compositing it from different parts of generated images. In our approach, users can first generate many results (roll the dice first) and then choose exactly what they want (composite across the dice rolls). Our key idea is to treat generated images as intermediate outputs, let users select desired parts from the generated results, and then composite the user-selected regions to form the final image. This approach allows users to take advantage of the model's generative capabilities while retaining fine-grained control over the final result.Method
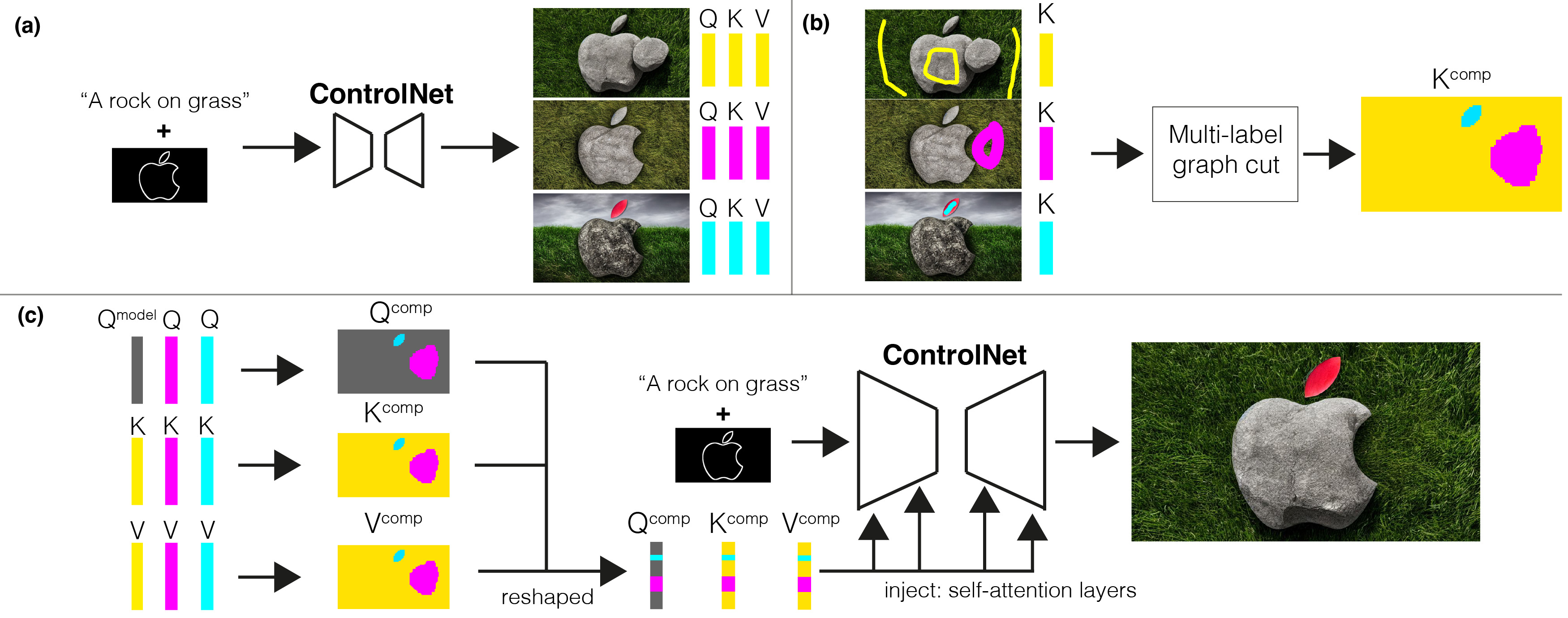
Our method takes in a stack of generated images and produces a final image based on sparse user strokes. (a) In our image stack, images are generated normally through ControlNet, using one or more prompts. The generated images share common spatial structures, as they are produced using the same input condition (e.g., edge maps or depth maps). (b) Upon browsing the image stack, the user selects desired objects and regions via broad brush strokes on the images. In the example below, the user wishes to remove the rock at the Apple bite in the first image and add the red leaf from the third image. To do so, the user draws strokes on the base rock in the first image, the patch of grass in the second image, and the red leaf in the third image. Our system takes the user input and performs a multi-label graph cut optimization in self-attention feature space (K features) to find a segmentation of image regions across the stack that minimizes seams. (c) The graph-cut result is then used to form composite Q, K, V features, which are then injected into the self-attention layers. The final image is a harmonious composite of the user-selected regions.
Results
By supporting the ability to combine generated images, Generative Photomontage allows users to achieve a wider range of results. Our method can be applied to a variety of use cases. Here, we highlight some use cases and show compelling results for each application.
Appearance Mixing
Here, we show applications in creative and artistic design, where users refine images based on subjective preference. This is useful in cases where the user may not realize what they want until they see it (e.g., creative exploration).
Shape and Artifacts Correction
While users can provide a sketch to guide ControlNet's output, ControlNet may fail to adhere to the user's input condition, especially when asked to generate objects with uncommon shapes. In such cases, our method can be used to "correct" object shapes and scene layouts, given a replaceable image patch within the stack.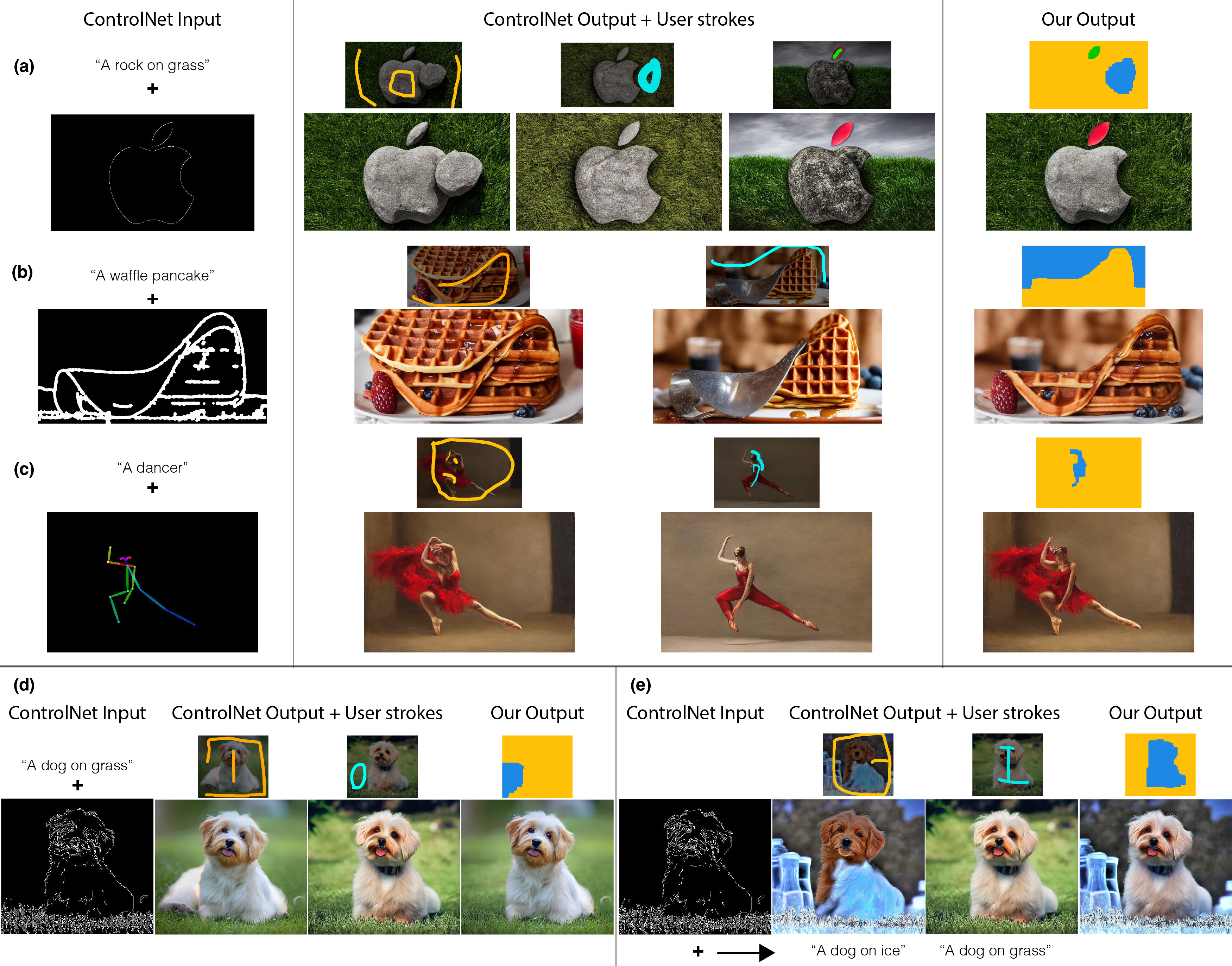
Prompt Alignment
In addition, Generative Photomontage can be used to increase prompt alignment in cases where the generated output does not accurately follow the input prompt. For example, it is difficult for ControlNet to follow all aspects of long complicated prompts (a). Using our method, users can create the desired image by breaking it up into simpler prompts and selectively combining the outputs (b).
Qualitative Comparison with Related Works
Below, we show qualitative comparisons between our method and related works. In Interactive Digital Photomontage [Agarwala et al. 2004], pixel-space graph-cut may cause seams to fall on undesired edges, and their gradient-domain blending in general does not preserve color, e.g., the bird's yellow beak is not preserved in (f). Blended latent diffusion [Avrahami et al. 2023] and MasaCtrl+ControlNet [Cao et al. 2023] may also lead to color changes (c, f) and structural changes (a, b, d, e).

Limitations
Our method assumes some spatial consistency among images in the stack. In cases where the images differ significantly in scene structure, our method may produce semantically incorrect outputs. (a) Two images have different horizons in the background. Naively combining two halves of the images leads to an inconsistent horizon (bottom left, circled red). Users can manually designate a consistent horizon by selecting the background of the second image (bottom, middle). (b) Alternatively, users can add a horizon in the input sketch to ControlNet to make it consistent across both images.

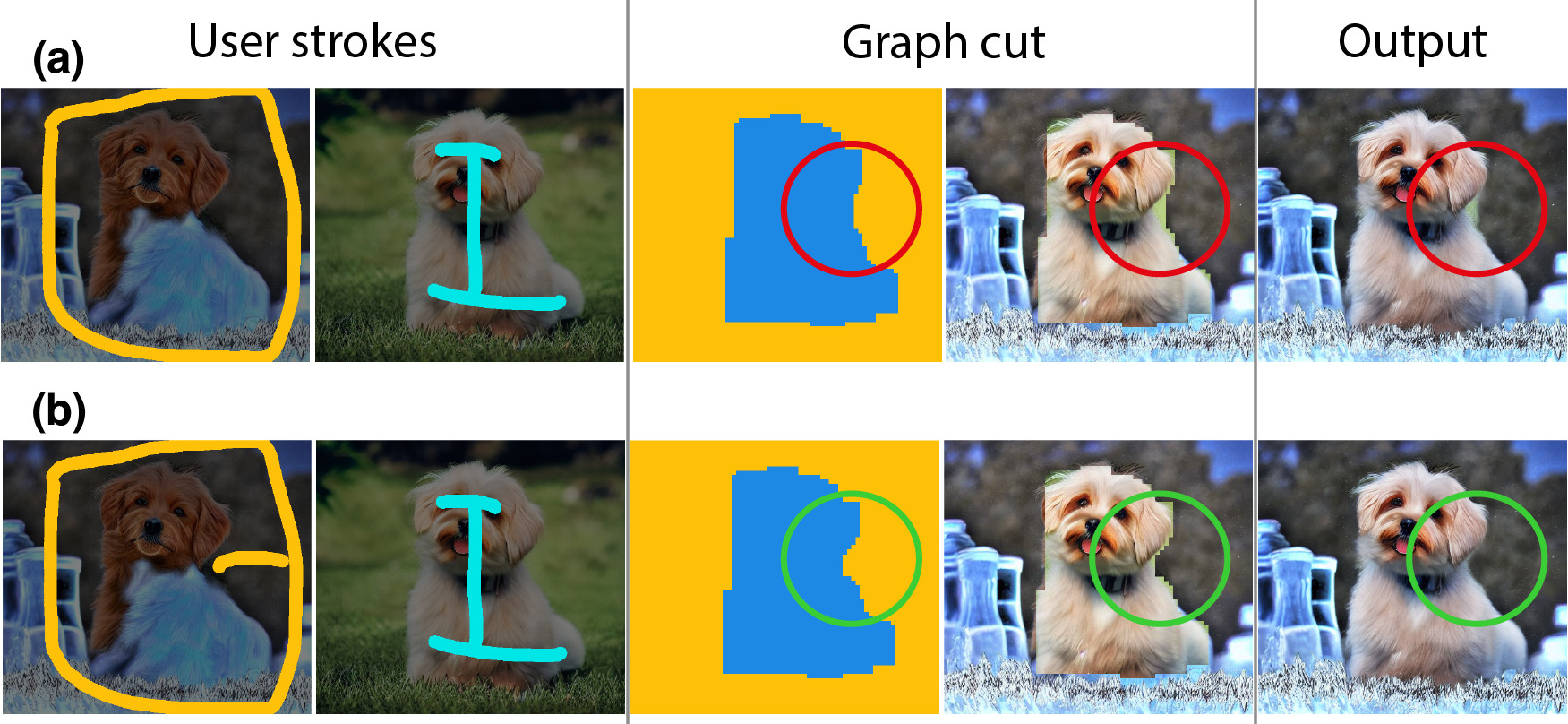
Second, our current graph cut parameters are empirically chosen to encourage congruous regions, which penalizes seam circumference. While this works well for many cases, if the target object has a curvy outline, it may require additional user strokes to obtain a finer boundary (see example below). Since graph cut solves in near real-time (~1s), users can quickly check the graph-cut result by visualizing it in image space and iterate as needed.
BibTex
@InProceedings{generativephotomontage,
author = {Liu, Sean J. and Kumari, Nupur and Shamir, Ariel and Zhu, Jun-Yan},
title = {Generative Photomontage},
booktitle = {Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR)},
month = {June},
year = {2025},
pages = {7931-7941},
}
Related & Concurrent Works
- Agarwala, Aseem, et al. "Interactive digital photomontage." ACM SIGGRAPH, 2004.
- Avrahami, Omri, Ohad Fried, and Dani Lischinski. "Blended latent diffusion." ACM Transactions on Graphics (TOG), 42(4), 2023.
- Cao, Mingdeng, et al. "Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing." IEEE International Conference on Computer Vision (ICCV), 2023
- Alaluf, Yuval, et al. "Cross-image attention for zero-shot appearance transfer." ACM SIGGRAPH, 2024.
- Hertz, Amir, et al. "Style aligned image generation via shared attention." IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024.
Acknowledgements
We are grateful to Kangle Deng for his help with setting up the user survey. We also thank Maxwell Jones, Gaurav Parmar, Sheng-Yu Wang, and Or Patashnik for helpful comments and suggestions. This project is partly supported by the Amazon Faculty Research Award, DARPA ECOLE, the Packard Fellowship, the IITP grant funded by the Korean Government (MSIT) (No. RS-2024-00457882, National AI Research Lab Project), and a joint NSFC-ISF Research Grant no. 3077/23. The website template is taken from CustomDiffusion.